如何做一个ai翻唱的视频
第一步 获取数据集
首先我们需要数据集(去训练自己要的角色的模型),简单来说,我们需要角色说话的录音。 那么怎么获取呢,可以直接伸手要(x,当然是自己去分离啦
使用MSST-WEBUI整合包,截至2025-2-3,已经是1.7.0了
作者 bilibili@Sucial丶
github项目开源地址
官方教程文档看这里
官方教程视频看这里
我的简易教程
- 打开教程文档,下载FULL版本setup(名字大概这样,版本可能不一样Setup_MSST_WebUI_1.7.0_v2_Full.exe)
- 打开教程文档,下载vocal_models的model_bs_roformer_ep_368_sdr_12.9628.ckpt模型分离人声和伴奏
- 打开教程文档,下载single_stem_models的deverb_bs_roformer_8_256dim_8depth.ckpt模型去混响
- 下载好setup后运行,安装我们的MSST-WEBUI
- 右键管理员第一次运行MSST-WEBUI
- 把模型放到你MSST-WEBUI程序目录下的pretrain文件夹的对应子文件夹
- 打开MSST-WEBUI的界面,根据需求配置下面的选项
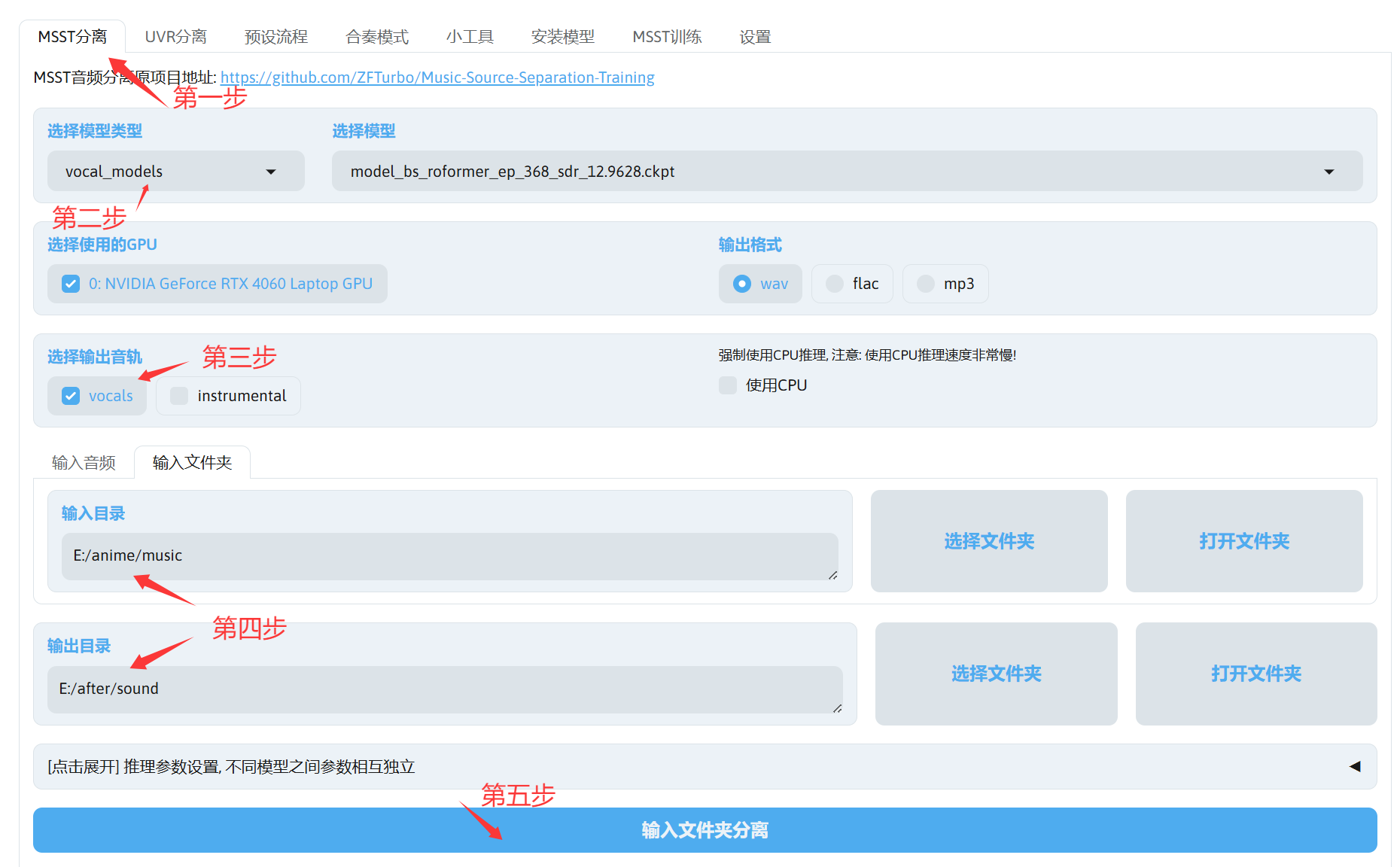
现在我们拿到我们的数据集了。好耶!
第二步 训练我们的模型,并得到我们的歌
我们获得的数据集肯定需要SVC(歌声转换)项目来训练自己的模型啦,那么有没有适合小白的整合包呢,有的兄弟有的
使用SVC Fusion整合包,集成了 So-VITS4.1,DDSP6.0,ReFlow-VAE-SVC 三个项目
截至2025-2-3,目前已经停更
易于使用 | 可用 CPU 训练 | 面向小白 歌声转换
Qt版本作者:bilibili@爱过_留过
文档地址
视频教程
我的简易教程:
- 打开官方文档下载最新的安装包
- 第一次运行,会提示缺少应用,我们直接按照指示下载
- 下载好后运行
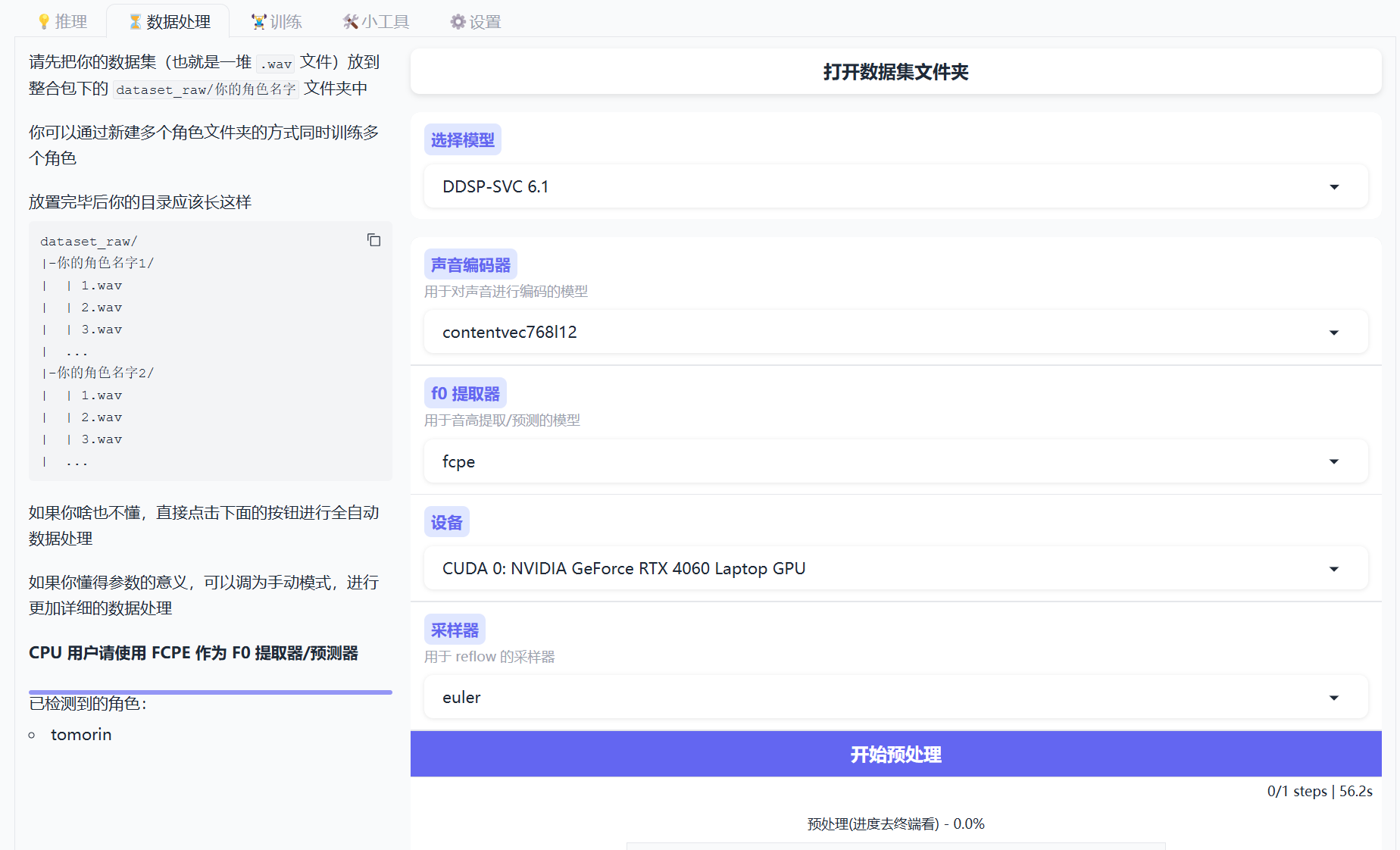
- 打开数据集文件夹,按照目录要求放入wav文件,基本默认配置是对的,直接点击开始预处理,等结果
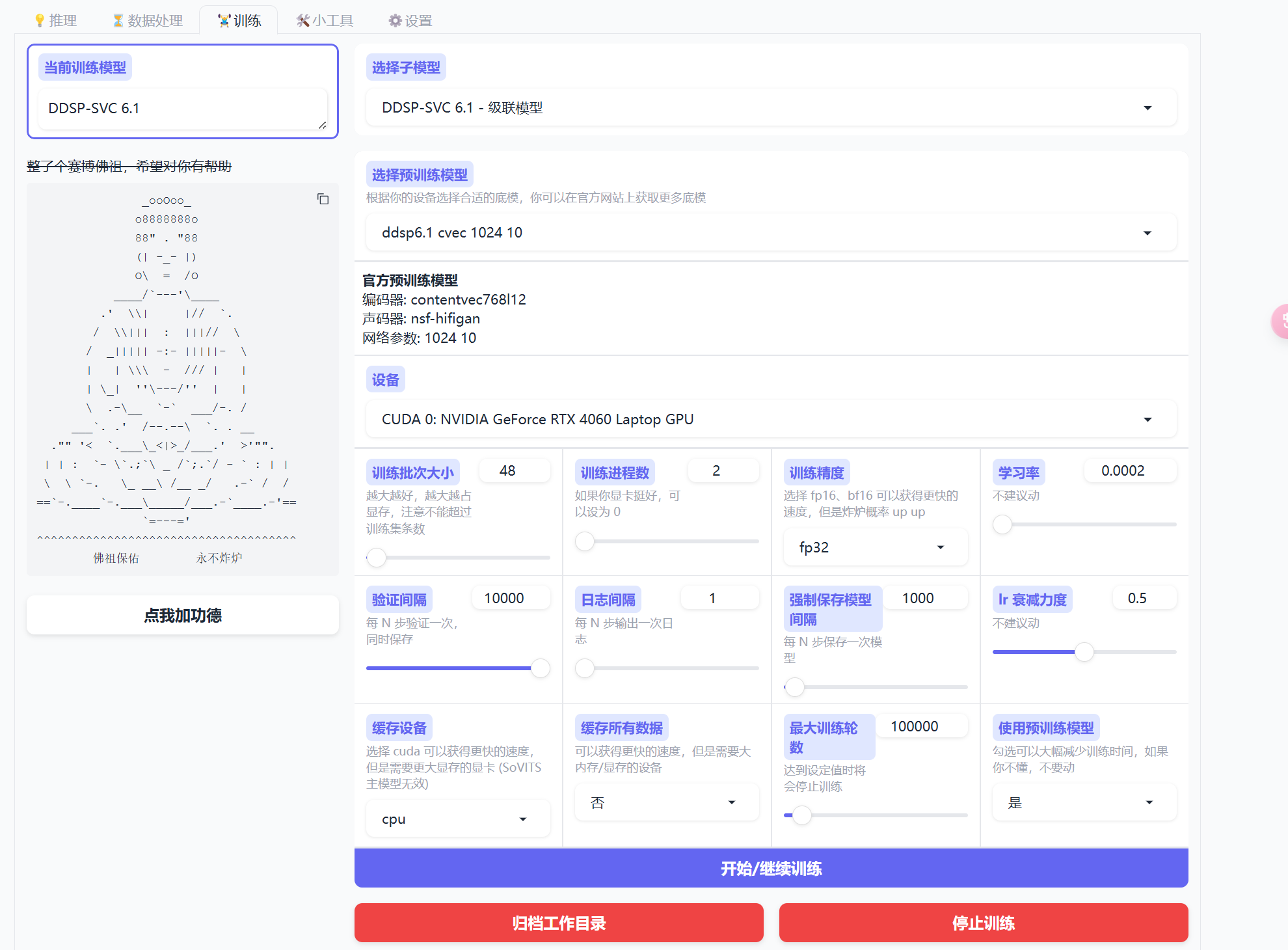
- 进入训练模块,点击开始训练(默认配置,如果懂得可以自己来)
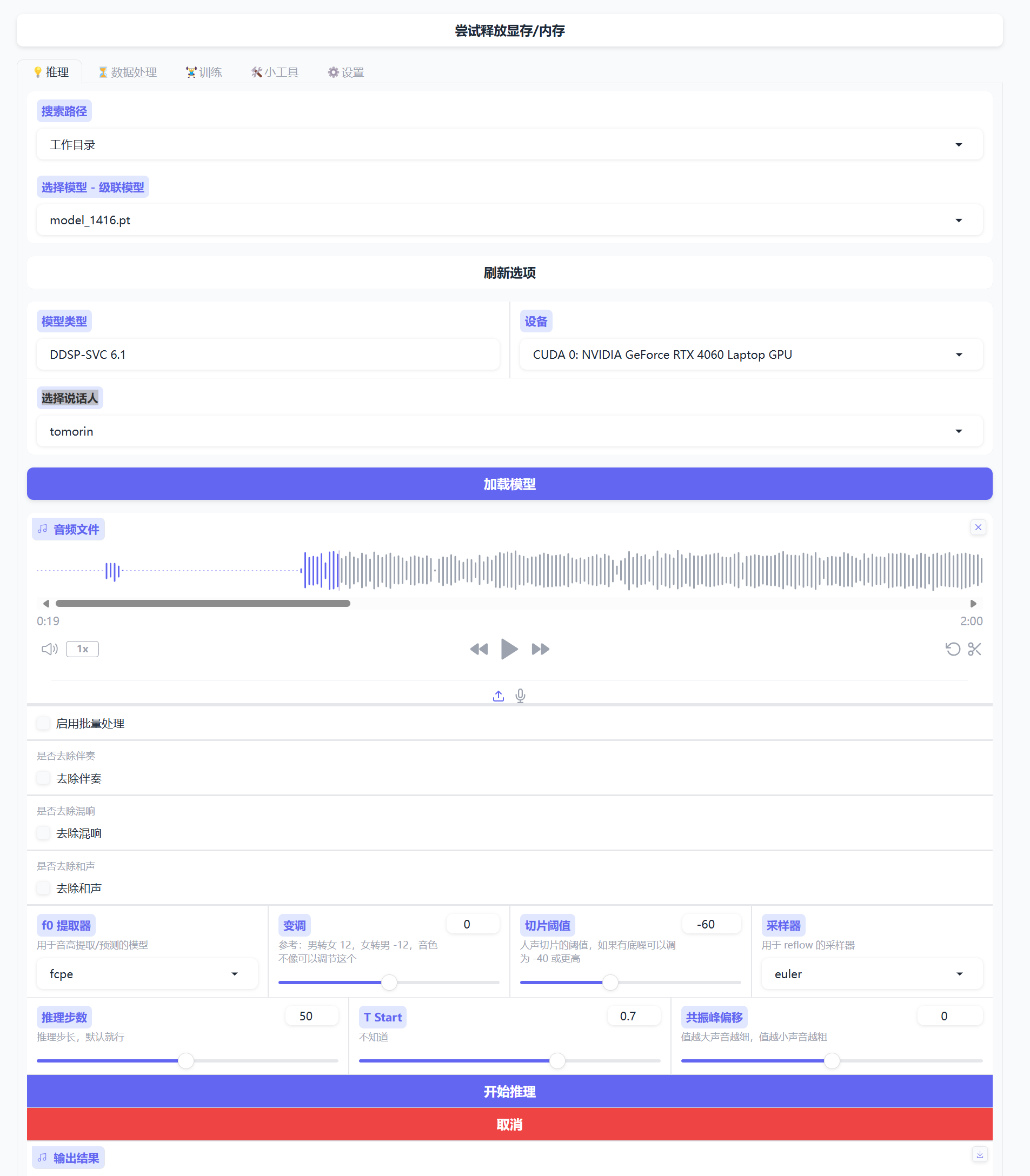
- 每1000步看一眼模型,如果够了就停。
- 进入推理模块,选择模型,选择说话人,加载模型,上传要让角色唱的歌,直接开始推理,等结果。